0、python基础语法
这个不在本文的讲解范围
1、正则表达式



2、爬虫代码实例
GET请求和POST请求的区别这里不做阐述了。
Post请求:
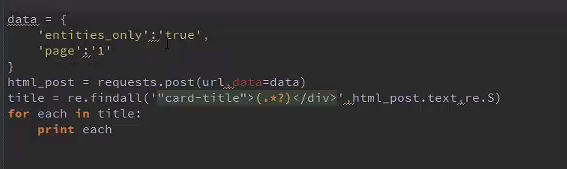
图片匹配:
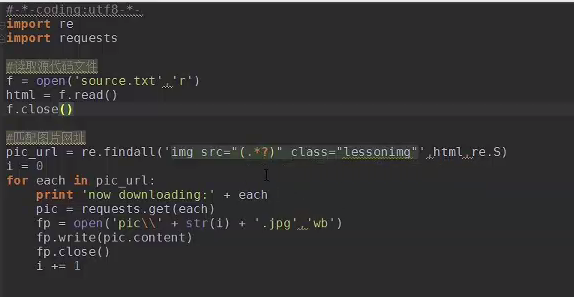
3、Scrapy爬虫编写原理
使用scrapy编写爬虫,爬取数据主要是一下四个步骤:
1、新建项目 (Project):新建一个新的爬虫项目。
2、明确目标(Items):明确你想要抓取的目标。
3、制作爬虫(Spider):制作爬虫开始爬取网页。
4、存储内容(Pipeline):设计管道存储爬取内容。
3.2、Scrapy项目文件的各个作用
scrapy.cfg:项目的配置文件
tutorial/:项目的Python模块,将会从这里引用代码
tutorial/items.py:项目的items文 件
tutorial/pipelines.py:项目的pipelines文件
tutorial/settings.py:项目的设置文件
tutorial/spiders/:存储爬虫的目录
4、Python爬虫框架Scrapy基础
在Windows下安装Scrapy(略)
4.1、在Ubuntu14.04下安装Scrapy
按照官方文档的说明,安装scrapy 需要以下程序或者库:
1、 Python 2.7
2、 Lxml
3、 OpenSSL
4、 Pip or easy_install Python package managers
通过命令检查系统所拥有的程序和库:python,import lxml,import OpenSSL。
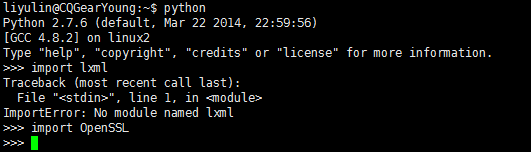
发现阿里云和线下的服务器均没有lxml库,所以先要安装lxml库:
#sudo apt-get install python-lxml


然后安装pip程序,pip 是安装python包的工具,提供了安装包,列出已经安装的包,升级包以及卸载包的功能。
#sudo apt-get install python-dev
#sudo apt-get install libevent-dev (这两个不是必要的,但最好安装,避免问题出现)
#apt-get install python-pip 安装pip程序
#apt-get install python-twisted 安装twisted,否则会出问题
#pip install Scrapy 安装Scrapy
5、Scrapy基本使用
5.1、创建项目
# scrapy startproject projectname
5.2、编写spider
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
对spider来说,爬取的循环类似下文:
1、以初始的URL初始化Request,并设置回调函数。 当该request下载完毕并返回时,将生成response,并作为参数传给该回调函数。spider中初始的request是通过调用 start_requests() 来获取的。 start_requests() 读取 start_urls 中的URL, 并以 parse 为回调函数生成 Request 。
2、在回调函数内分析返回的(网页)内容,返回 Item 对象或者 Request 或者一个包括二者的可迭代容器。 返回的Request对象之后会经过Scrapy处理,下载相应的内容,并调用设置的callback函数(函数可相同)。
3、在回调函数内,您可以使用 选择器(Selectors) (您也可以使用BeautifulSoup, lxml 或者您想用的任何解析器) 来分析网页内容,并根据分析的数据生成item。
4、最后,由spider返回的item将被存到数据库(由某些 Item Pipeline 处理)或使用 Feed exports 存入到文件中。
Spider的参数
一个简单的例子:
import scrapy #导入
class testspider(scrapy.Spider): #继承父类Spider
name = "test" #这个name是该spider的唯一名称
allowed_domains = ["biketo.com"] #可选。包含了spider允许爬取的域名(domain)列表(list)。 当 OffsiteMiddleware 启用时, 域名不在列表中的URL不会被跟进。
start_urls = [ #URL列表
"http://www.biketo.com/racing/",
"http://www.biketo.com/racing/news/"
]
def parse(self, response): #当response没有指定回调函数时,该方法是Scrapy处理下载的response的默认方法。
# filename = response.url.split("/")[-2]
# with open(filename, 'wb') as f:
# f.write(response.body)
for sel in response.xpath('/html/head/link'):
# title = sel.xpath('/title/text()').extract()
link = sel.xpath('@href').extract()
print link
#以下参数自行看文档
Custom_settings
Crawler
Setting
from_crawler(crawler, *args, **kwargs)
start_requests() #后有POST登录例子
make_requests_from_url(url)
log(message[, level, component])
closed(reason)
在单个回调函数中返回多个request以及Item的例子:
def parse(self, response):
sel = scrapy.Selector(response)
for h3 in response.xpath('//h3').extract():
yield MyItem(title=h3)
for url in response.xpath('//a/@href').extract():
yield scrapy.Request(url, callback=self.parse)
self.log('A response from %s just arrived!' % response.url)
CrawlSpider参数
配合rule使用CrawlerSpider的例子:
import scrapy
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors import LinkExtractor
class MySpider(CrawlSpider):
name = 'example.com'
allowed_domains = ['example.com']
start_urls = ['http://www.example.com']
rules = (
# 提取匹配 'category.php' (但不匹配 'subsection.php') 的链接并跟进链接(没有callback意味着follow默认为True)
Rule(LinkExtractor(allow=('category\.php', ), deny=('subsection\.php', ))),
# 提取匹配 'item.php' 的链接并使用spider的parse_item方法进行分析
Rule(LinkExtractor(allow=('item\.php', )), callback='parse_item'),
)
def parse_item(self, response):
self.log('Hi, this is an item page! %s' % response.url)
item = scrapy.Item()
item['id'] = response.xpath('//td[@id="item_id"]/text()').re(r'ID: (\d+)')
item['name'] = response.xpath('//td[@id="item_name"]/text()').extract()
item['description'] = response.xpath('//td[@id="item_description"]/text()').extract()
return item
参数图解爬取规则:

XMLFeedSpider参数
被设计用于通过迭代各个节点来分析XML源(XML feed)。
CSVFeedSpider参数
该spider除了其按行遍历而不是节点之外其他和XMLFeedSpider十分类似。 而其在每次迭代时调用的是 parse_row() 。
SitemapSpider参数
SitemapSpider使您爬取网站时可以通过 Sitemaps 来发现爬取的URL。
其支持嵌套的sitemap,并能从 robots.txt 中获取sitemap的url
以上详情参考《内置Spider参考手册》
6、选择器(Selectors)
xpath():返回一系列的selectors,每一个select表示一个xpath参数表达式选择的节点
css():返回一系列的selectors,每一个select表示一个css参数表达式选择的节点
extract():返回一个unicode字符串,为选中的数据
re():返回一串一个unicode字符串,为使用正则表达式抓取出来的内容
当抓取网页时,你做的最常见的任务是从HTML源码中提取数据。现有的一些库可以达到这个目的:
BeautifulSoup 是在程序员间非常流行的网页分析库,它基于HTML代码的结构来构造一个Python对象, 对不良标记的处理也非常合理,但它有一个缺点:慢。
lxml 是一个基于 ElementTree (不是Python标准库的一部分)的python化的XML解析库(也可以解析HTML)。
Scrapy提取数据有自己的一套机制。它们被称作选择器(seletors),因为他们通过特定的 XPath 或者 CSS 表达式来“选择” HTML文件中的某个部分。

从语法上看,这两种选择器在某些情况下的具有相似性,尤其是’>’和’/’两者之间。虽然他们并不总是有着相同的功能(XPath中要取决于正在使用的轴),但通常情况下他们指的都是某个父元素的子元素。还有,空白符’ ‘和’//’都意味着当前元素的所有后代元素。最后是星号’*’,类似于通配符,表示所有元素,而不管是哪种标签名。
XPath根据Class获取元素的原来的写法://*[contains(@class,'foo')]
网上网友实验更正:
//*[@class='foo' or contains(@class,' foo ') or starts-with(@class,'foo ') or substring(@class,string-length(@class)-3)=' foo']
一个元素的class属性中如果包含’foo’,可能有四种情况:

7、关于Json格式的数据爬取
7.1、网页数据分析
使用火狐的扩展工具firedebug,查看网页结构,抓取到json的请求链接。如果是post请求,则需设置用户和密码,进行模拟登录。
如果是get请求,则可以直接对url进行request请求、解析、数据爬取。
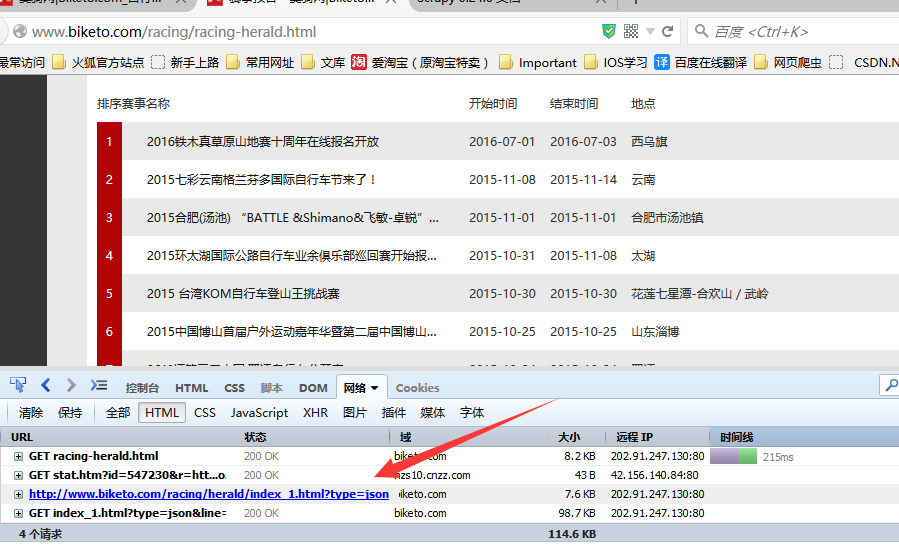
核心代码
import json postLists = json.loads(response.body_as_unicode(), encoding="utf-8")
注:要注意编码格式
8、Scrapy数据写入数据库
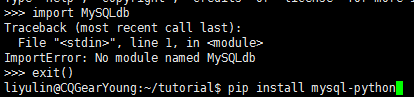
8.1、Python安装mysql支持
#pip install mysql-python 或者先sudo apt-get install python-mysqldb再--- 报错EnvironmentError: mysql_config not found, 则 #sudo apt-get install libmysqlclient-dev 检测是否支持:import MySQLdb
如若出错,则:
8.2、创建数据库与表
CREATE DATABASE liyulin DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
8.3、Scrapy设置mysql配置信息
可以在piplines.py中配置,但为了方便管理,所以在setting.py中配置数据库信息:
#start MySQL database configure setting MYSQL_HOST = '192.168.1.112' MYSQL_DBNAME = 'liyulin' MYSQL_USER = 'root' MYSQL_PASSWD = 'cqgearyoung2015' MYSQL_PORT = '3306' DB_PREFIX = 'crawler_' #end of MySQL database configure setting
按照网上教程实现,可能会出现错误:

,这个暂时不作深入学习,就直接写在pipline.py文件中。
def __init__(self):
self.dbpool = adbapi.ConnectionPool('MySQLdb',
host='192.168.1.112',
db='liyulin',
user='root',
passwd='cqgearyoung2015',
charset='utf8',
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=True,
)
在pipline.py文件中编写类,MySQLStoreTestPipline(名字随便),主要实现两个功能:
1、如果url不存在则直接写入数据库,如果url存在则更新,通过自定义的方法_do_upinsert实现。 2、确保url唯一性的md5函数_get_linkmd5id 。
详情见代码文件。
9、Scrapy 下载项目图片
Scrapy提供了一个 item pipeline ,来下载属于某个特定项目的图片,比如,当你抓取产品时,也想把它们的图片下载到本地。
这条管道,被称作图片管道,在 ImagesPipeline 类中实现,提供了一个方便并具有额外特性的方法,来下载并本地存储图片:
将所有下载的图片转换成通用的格式(JPG)和模式(RGB)
避免重新下载最近已经下载过的图片
缩略图生成
检测图像的宽/高,确保它们满足最小限制
这个管道也会为那些当前安排好要下载的图片保留一个内部队列,并将那些到达的包含相同图片的项目连接到那个队列中。 这可以避免多次下载几个项目共享的同一个图片。
Pillow 是用来生成缩略图,并将图片归一化为JPEG/RGB格式,因此为了使用图片管道,你需要安装这个库。 Python Imaging Library (PIL) 在大多数情况下是有效的,但众所周知,在一些设置里会出现问题,因此我们推荐使用 Pillow 而不是PIL.
环境搭建Pillow

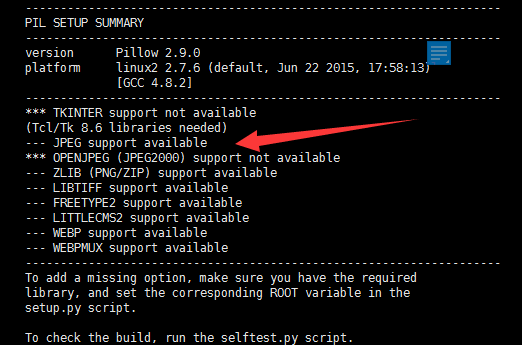
如果上图中JPEG不支持的话,就要安装相关的支持库,并重新安装pillow。
注:重新安装pillow的时候,要完全删除PIL文件夹,(系统不会将旧PIL文件覆盖)。

核心代码
Pipline.py:
class PycrawlTestPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['image_url']:
yield scrapy.Request(image_url)
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
item['image_path'] = image_paths
return item
settings:
IMAGE_STROE = “/usr/share/crawl/tu/tu/images” 图片的保存路径。
10、Scrapy爬虫防止被ban
防止Scrapy爬虫被ban,主要有一下几个策略:
动态随机设置user agent、禁用cookies、设置延迟下载、使用Google cache、使用IP地址池(Tor project、VPN和代理IP)、使用crawlera。
1、scrapy代理IP、user agent的切换都是通过DOWNLOADER_MIDDLEWARES进行控制,创建middlewares.py文件:
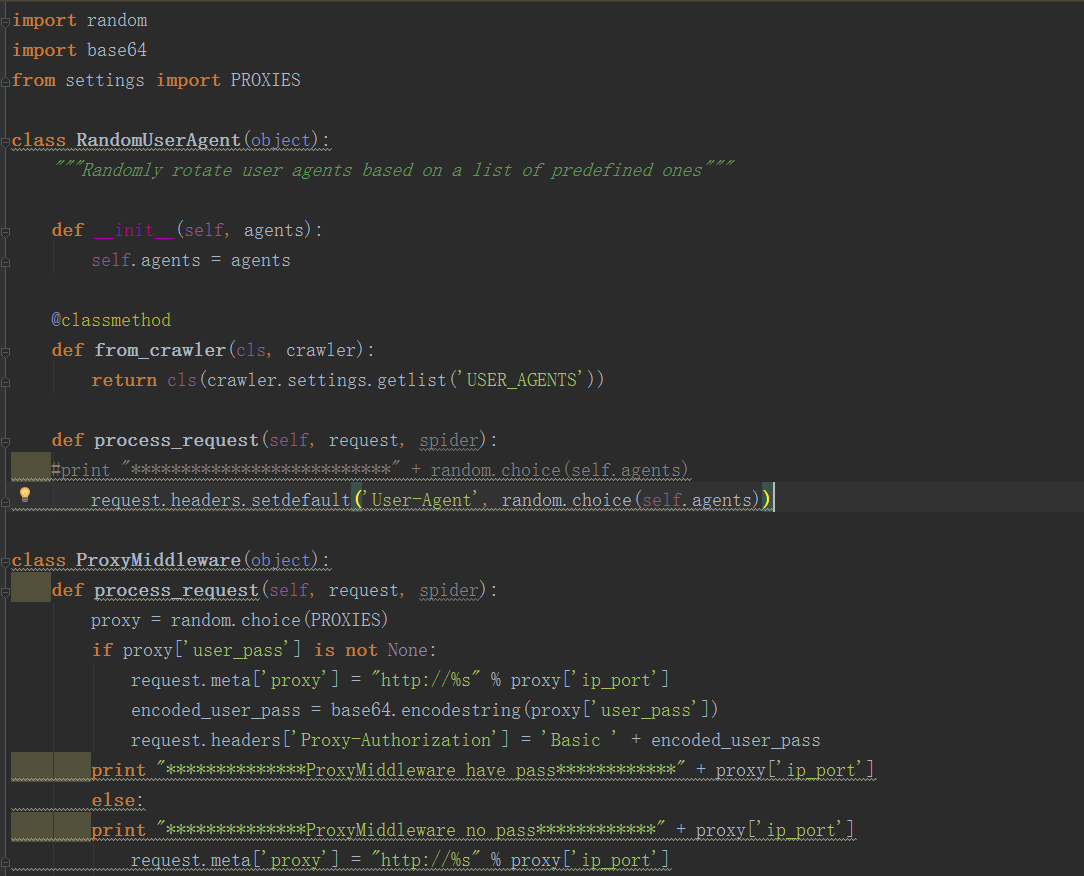
2、类RandomUserAgent主要用来动态获取user agent,user agent列表USER_AGENTS在settings.py中进行配置。类ProxyMiddleware用来切换代理,proxy列表PROXIES也是在settings.py中进行配置。
3、禁用cookies;设置下载延迟;最后设置DOWNLOADER_MIDDLEWARES
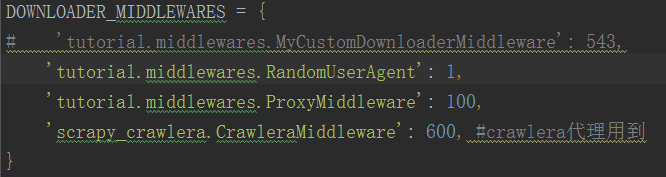
利用第三方平台crawlera做Scrapy爬虫防屏蔽。
1、 注册Crawlera账号,获取crawlera API KEY
2、 修改Scrapy项目
安装Scrapy-crawlera: #pip install scrapy-crawlera
11、参考文献
安装教程:http://cuiqingcai.com/912.html
极客教程:http://www.jikexueyuan.com/path/python/
Python官网:https://www.python.org/
集成环境软件:http://www.jetbrains.com/
(以下5个博客看完基本上就会写一个基本的爬虫了)
博客:http://www.cnblogs.com/rwxwsblog/p/4557123.html 安装
http://www.cnblogs.com/rwxwsblog/p/4567052.html 数据爬取
http://www.cnblogs.com/rwxwsblog/p/4572367.html 数据库写入
http://www.cnblogs.com/rwxwsblog/p/4575894.html 防被ban
http://www.tuicool.com/articles/7ZnYJb2 爬虫代理
Python爬虫入门:http://blog.csdn.net/column/details/why-bug.html
http://cuiqingcai.com/category/technique/python
Python 爬虫数据存入数据库:http://www.tuicool.com/articles/EjYBRz
http://www.w2bc.com/Article/44862
添加模块路径:http://blog.csdn.net/fengqingting2/article/details/20695975
安装ssh模块:http://blog.chinaunix.net/uid-24917554-id-3476396.html
安装Scrapy:http://scrapy-chs.readthedocs.org/zh_CN/latest/intro/overview.html
Crawlera 爬虫代理:http://www.tuicool.com/articles/7ZnYJb2
资源下载:
Python官网:https://www.python.org/downloads/
lxml下载:https://pypi.python.org/pypi/lxml/2.3/
twisted下载:http://twistedmatrix.com/trac/wiki/Downloads
Scrapy教程:http://scrapy-chs.readthedocs.org/zh_CN/latest/intro/overview.html