REmote DIctionary Server(Redis) 是一个由 Salvatore Sanfilippo 写的 key-value 存储系统,是跨平台的非关系型数据库。
Redis模型:
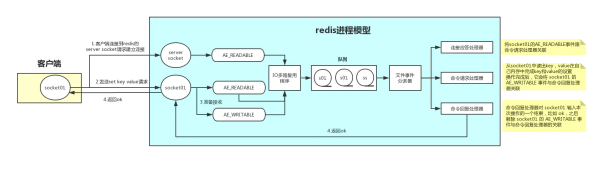
Redis基于Reactor模式开发了网络事件处理器,这个处理器被称为文件事件处理器。
redis 内部使用文件事件处理器 file event handler,这个文件事件处理器是单线程的,所以 redis 才叫做单线程的模型。
它采用 IO 多路复用机制同时监听多个 socket,根据 socket 上的事件来选择对应的事件处理器进行处理。
文件书简你处理器组成:
- 多个socket
- IO多路复用程序
- 文件事件分派器
- 事件处理器(包括:连接应答处理器、命令请求处理器、命令回复处理器)
效率高的原因:
- 纯内存操作
- 核心是基于非阻塞的 IO 多路复用机制
- 单线程反而避免了多线程的频繁上下文切换问题
数据存储格式:
- redis自身是一个Map,其中所有的数据都是采用key:value的形式存储
- 数据类型指的是存储的数据的类型,也就是value部分的类型,key部分永远都是字符串
5种数据类型:Hash,String,List,Set,ZSet
详细数据类型和应用场景可参考:https://blog.csdn.net/Doub1eFAN/article/details/107584068
redis持久化:Redis所有数据保存在内存中,对数据的更新将异步地保存到磁盘上,使得数据在Redis重启之后仍然存在。
redis持久化的两种方式:
- 快照持久化:将Redis某一时刻存在的所有数据都写入硬盘。RDB,手动执行save(同步)或者bgsave(异步)
- AOF持久化:AOF的全称叫append-only file,中文意思是只追加文件。当使用AOF持久化方式的时候,Redis执行写命令的时候,将被执行的写命令复制到硬盘里面,说的通俗一点就是写日志。
击穿:单个key在缓存中查不到,去数据库查询,这样如果数据量不大或者并发不大的话是没有什么问题的。如果数据库数据量大并且是高并发的情况下那么就可能会造成数据库压力过大而崩溃。
击穿解决方案:
- 通过synchronized+双重检查机制:某个key只让一个线程查询,阻塞其它线程
- 设置value永不过期
- 使用互斥锁(mutex key) : 就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法
雪崩:多个key查询并且出现高并发,缓存中失效或者查不到,然后都去db查询,从而导致db压力突然飙升,从而崩溃。原因:key同时失效,redis本身崩溃。
雪崩解决方案:
- 在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
- 可以通过缓存reload机制,预先去更新缓存,再即将发生大并发访问前手动触发加载缓存
- 不同的key,设置不同的过期时间
- 做二级缓存,或者双缓存策略。A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期。
穿透:一般是出现这种情况是因为恶意频繁查询才会对系统造成很大的问题: key缓存并且数据库不存在,所以每次查询都会查询数据库从而导致数据库崩溃。
穿透解决方案:
- 使用布隆过滤器: 热点数据等场景
- 将击透的key缓存起来,但是时间不能太长,下次进来是直接返回不存在
单线程的Redis速度快的原因
- 纯内存操作
- IO多路复用
IO并发性能提升解决方案:多进程、多线程、基于单进程的IO多路复用(select/poll/epoll)
进程是并发执行的程序在执行过程中分配和管理资源的基本单位,是一个动态概念,竞争计算机系统资源的基本单位。
线程是进程的一个执行单元,是进程内科调度实体,是运行在进程上下文的逻辑流。比进程更小的独立运行的基本单位。线程也被称为轻量级进程。
IO多路复用就是一个服务端进程可以同时处理多个套接字描述符
- 多路:多个客户端连接(连接就是套接字描述符)
- 复用:使用单进程就能够实现同时处理多个客户端的连接
三个阶段select/poll/epoll:
- select就是轮询,在Linux上限制个数一般为1024个
- poll解决了select的个数限制,但是依然是轮询
- epoll解决了个数的限制,同时解决了轮询的方式
Redis 6.0 之后的版本开始选择性使用多线程模型。

